ACI Multi Pod Overview, Requirements and Basics
Reference Note: This post consist of notes and heavily based on the ACI MultiPod latest White paper.
Contents
ACI MultiPod Overview
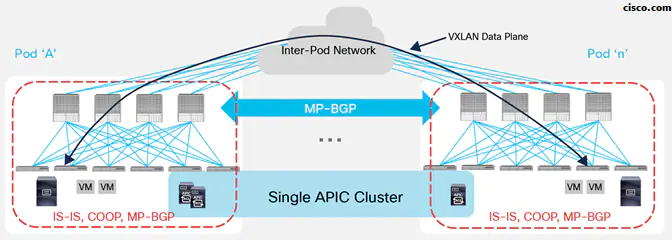
ACI Multi-Pod allows ACI Stretched Fabric architecture and permits central management of separate ACI networks. A Single APIC Cluster is shared between multiple ACI Pods.
Even if the various Pods are managed and operate as a single distributed ACI fabric, Multi-Pod provides the capability of increasing failure domain isolation across Pods through separation of the fabric control plane protocols: Different instances of IS-IS, COOP, and MP-BGP protocols run inside each Pod so that faults and issues with any of those protocols would be contained in the single Pod and not spread across the entire Multi-Pod fabric.
Please refer to the guide below for ACI Multipod basic configuration:
How Pods are connected in an ACI MultiPod design
Inter-Pod Network (IPN):
- The different ACI Pods are interconnected by leveraging an “Inter-Pod Network” (IPN). Each Pod connects to the IPN through the spine nodes, the IPN can be as simple as a single Layer 3 device or can be built with a larger Layer 3 network infrastructure like a Service Provider network.
- The IPN must simply provide basic Layer 3 connectivity services, allowing for the establishment across Pods of spine-to-spine and leaf-to-leaf VXLAN tunnels.
ACI MutiPod IPN Requirements:
- Which IPN routers are the most recommended by Cisco:
The recommendation is to deploy, when possible, switches of the Cisco Nexus® 9200 family or switches of the Cisco Nexus 9300 second-generation family (i.e., EX models or newer).
- In order to perform Inter Pod connectivity functions, the IPN must support a few specific functionalities:
– Multicast support:
In order to handle BUM Traffic in a single ACI Fabric, a unique multicast group is associated with each defined Bridge Domain and takes the name of Bridge Domain Group IP outer (also called BD GIPo).
The same behavior must be achieved for endpoints part of the same Bridge Domain that is connected to different Pods. In order to flood the BUM traffic across Pods, the same multicast group used inside the Pod is also extended through the IPN network. Those multicast groups should work in PIM Bidir mode and must be dedicated to this function (i.e. not used for other purposes, applications, etc.).
– DHCP relay support:
One of the functionalities offered by the ACI Multi-Pod solution is the capability of allowing auto-provisioning of configuration for all the ACI devices deployed in remote Pods. This gives those remote Pods the ability to join the Multi-Pod fabric with zero-touch configuration.
This functionality relies on the capability of the first IPN device (Router) connected to the spines of the remote Pod to relay DHCP requests generated from new starting ACI spines toward the APIC controllers active in the first Pod using the APICs Infra IPs.
– OSPF support:
OSPFv2 is the routing protocol (in addition to static routing) supported on the spine interfaces connecting to the IPN devices.
– Increased MTU:
VXLAN data-plane traffic is exchanged between Pods, the IPN must ensure to be able to support an increased MTU on its physical connections, in order to avoid the need for fragmentation and reassembly.
Note that The VXLAN encapsulation header adds 50 Bytes to the overall size of an Ethernet frame. This implies an additional MTU size of 50 Bytes on the IPN side.
– Sub-interface and VLAN 4 Tag:
Traffic originating from the spine interfaces is always tagged with an 802.1q VLAN 4 value, which implies the need to define and support Layer 3 sub-interfaces on both the spines and the directly connected IPN devices.
ACI MultiPod IPN Control Plane:
In a Multi-Pod deployment, each Pod is assigned a separate and not overlapping TEP pool, as shown in the Figure below (Cisco):
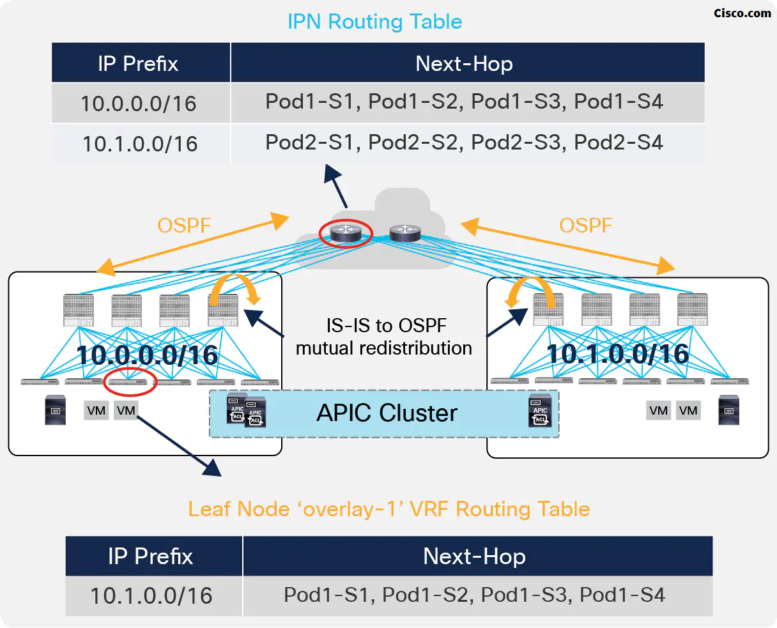
The spines in each Pod establish OSPF peerings with the directly connected IPN devices to be able to send out the TEP pool prefix for the local Pod. As a consequence, the IPN devices install in their routing tables equal-cost routes for the TEP pools valid in the different Pods.
At the same time, the TEP-Pool prefixes relative to remote Pods received by the spines via OSPF are redistributed into the IS-IS process of each Pod so that the leaf nodes can install them in their routing table (those routes are part of the ‘overlay-1’ VRF representing the infrastructure VRF).
IPN Multicast support:
In ACI, BUM traffic can be exchanged across Layer 3 network boundaries by encapsulating it into VXLAN packets addressed to a multicast group, so to leverage the network for traffic replication services.
Each Bridge Domain has associated a separate multicast group (named ‘GIPo’) to ensure granular delivery of multi-destination frames only to the endpoints that are part of a given Bridge Domain.
A similar behavior must be achieved when extending the Bridge Domain connectivity across Pods. This implies the need to extend multicast connectivity through the IPN network, which is the reason why those devices must support PIM Bidir:
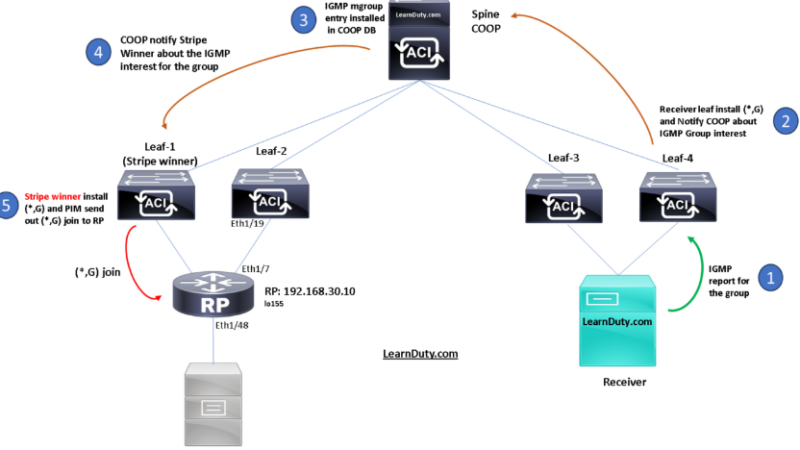
Delivery of BUM Traffic between Pods:
1. EP1 belonging to BD1 originates from a BUM frame.
2. The frame is encapsulated by the local leaf node and destined to the multicast group GIPo1 associated with BD1. As a consequence, it is sent along with one of the multi-destination FTAG trees assigned to BD1 and reaches all the local spine and leaf nodes where BD1 has been instantiated.
3. Spine 1 is responsible for forwarding BUM traffic for BD1 toward the IPN devices, leveraging the specific link connected to IPN1.
4. The IPN receives the traffic and performs multicast replication toward all the Pods from which it received an IGMP Join for GIPo1. This ensures that BUM traffic is sent only to Pods where BD1 is active (i.e. there is at least an endpoint actively connected in the Bridge Domain).
5. The spine that sent the IGMP Join toward the IPN devices receives the multicast traffic and forwards it inside the local Pod along with one of the multi-destination trees associated with BD1. All the leafs where BD1 has been instantiated receive the frame.
6. The leaf where EP2 is connected also receives the stream, decapsulates the packet, and forwards it to EP2.
Pod Auto-Provisioning
- DHCP and TFTP:
The following sequence of steps allows Pod2 to join the Multi-Pod fabric:
1. The first spine in Pod2 boots up and starts sending DHCP requests out of every connected interface. This implies that the DHCP request is also sent toward the IPN devices.
2. The IPN device receiving the DHCP request has been configured to relay that message to the APIC node(s) deployed in Pod 1.
The spine’s serial number is added as a TLV of the DHCP request sent at the step above, so the receiving APIC can add this information to its Fabric Membership table.
3. Once a user explicitly configure onto the APIC Fabric Membership table the discovered spine ( give a name and id) , the APIC replies back with an IP address to be assigned to the spine’s interfaces facing the IPN. Also, the APIC provides information about a bootstrap file (and the TFTP server where to retrieve it (which is the APIC itself) that contains the required spine configuration to set up its VTEP interfaces and OSPF/MP-BGP adjacencies.
4. The spine connects to the TFTP server to pull the full configuration.
5. The APIC (TFTP server) replies with the full configuration. At this point, the spine has joined the Multi-Pod fabric and all the policies configured on the APIC controller are pushed to that device.
6. The other spine and leaf nodes in Pod2 would now go through the usual process used to join an ACI Fabric (obtain a TEP via DHCP from APIC). At the end of this process, all the devices part of Pod2 are up and running and the Pod fully joined the Multi-Pod fabric.
Please note that For the APIC in other pods to join the cluster, It need to be configured in seed pod TEP range, hence, a host route is needed (the leaf connected to Pod-1 APIC will have a static route /32 pointing to the APIC (in pod-2) IP, this route is redistributed into IS-IS and reach therefore APIC in Pod-1 and remote Pod will have connectivity.
- Multi Pod Configuration Zones:
Using Configuration Zones lets you test the configuration changes on that subset of leafs and servers before applying them to the entire fabric. Configuration zoning is only applied to changes made at the infrastructure level (i.e. applied to policies in the “Infra” Tenant). This is because a mistake in such configuration would likely affect all the other Tenants deployed on the fabric.
Each zone can be in one of these “deployment” modes:
● Disabled: Any update to a node part of a disabled zone will be postponed till zone deployment mode is changed or the node is removed from the zone.
● Enabled: Any update to a node part of an enabled zone will be immediately sent. This is the default behavior. A node not part of any zone is equivalent to a node part of a zone set to enabled.
Changes to the infrastructure policies are immediately applied to nodes that are members of a deployment mode-enabled zone. These same changes are queued for the nodes that are members of a zone with deployment mode disabled.
Inter-Pods MP-BGP Control Plane
- Since each Pod is running a separate instance of the COOP protocol, this implies that information about discovered endpoints (MAC, IPv4/IPv6 addresses, and their location) is only exchanged using COOP as a control plane protocol between the leaf and spine nodes locally deployed in each Pod.
- ACI Multi-Pod functions as a single fabric, so, it is key to ensure that the databases implemented in the spine nodes across Pods have a consistent view of the endpoints connected to the fabric, this requires the deployment of an overlay control plane running between the spines and used to exchange endpoint reachability information.
Multi-Protocol BGP has been chosen for this function. This is due to the flexibility and scalability properties of this protocol and its support of different address families (like EVPN and VPNv4) allowing the exchange of Layer 2 and Layer 3 information in a true multi-tenant fashion.
➜ An independent instance of the COOP protocol is running between the leaf and spine nodes in each Pod, hence the MP-BGP EVPN control plane between spines is introduced for synchronizing reachability information across Pods.
- MP-BGP Control Plane across Pods:
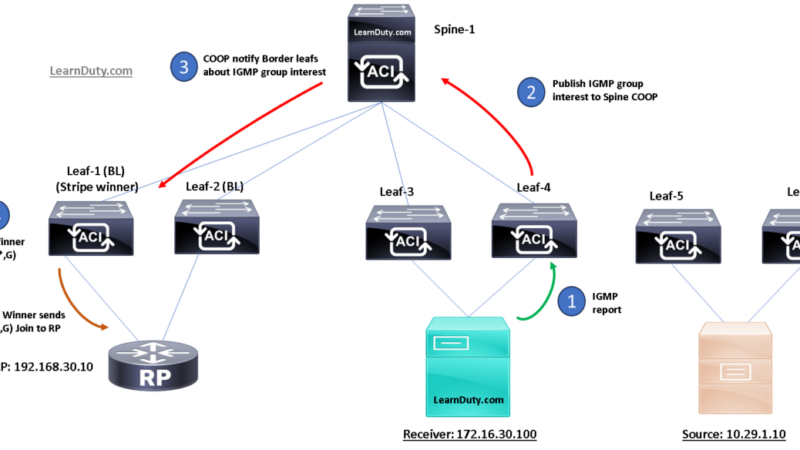
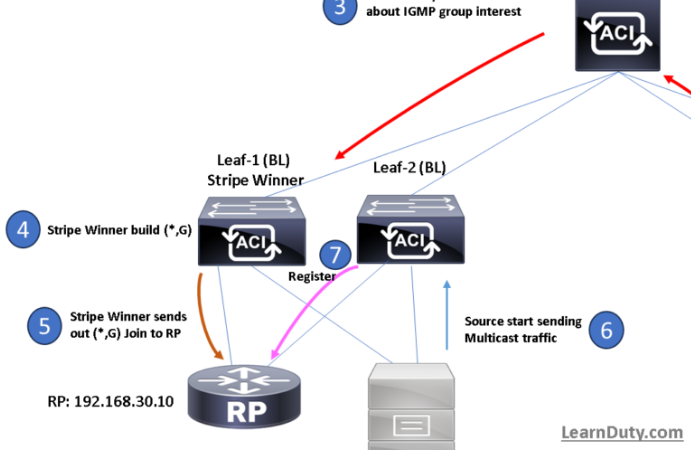
1. An endpoint EP1 connects to Leaf 1 in Pod1. The leaf discovers the endpoint and sends a COOP control plane message to the Anycast VTEP address representing all the local spines.
2. The receiving spine adds the endpoint information to the COOP database and synchronizes the information to all the other local spines. EP1 is associated with the VTEP address identifying the local leaf nodes where it is connected.
3. Since this is the first time the endpoint is added to the local COOP database, an MP-BGP update is sent to the remote spine nodes to communicate the endpoint information.
4. The receiving spine node adds the information to the COOP database and synchronizes it to all the other local spine nodes. EP1 is now associated with an Anycast VTEP address (“Proxy A”) available on all the spine nodes deployed in Pod1.
In simple words, there is a redistribution from COOP to EVPN in the local EP Pod and on the other side, the MP-BGP EVPN is redistributed into COOP, As a result, the independent COOP Database are consistent across Pods.
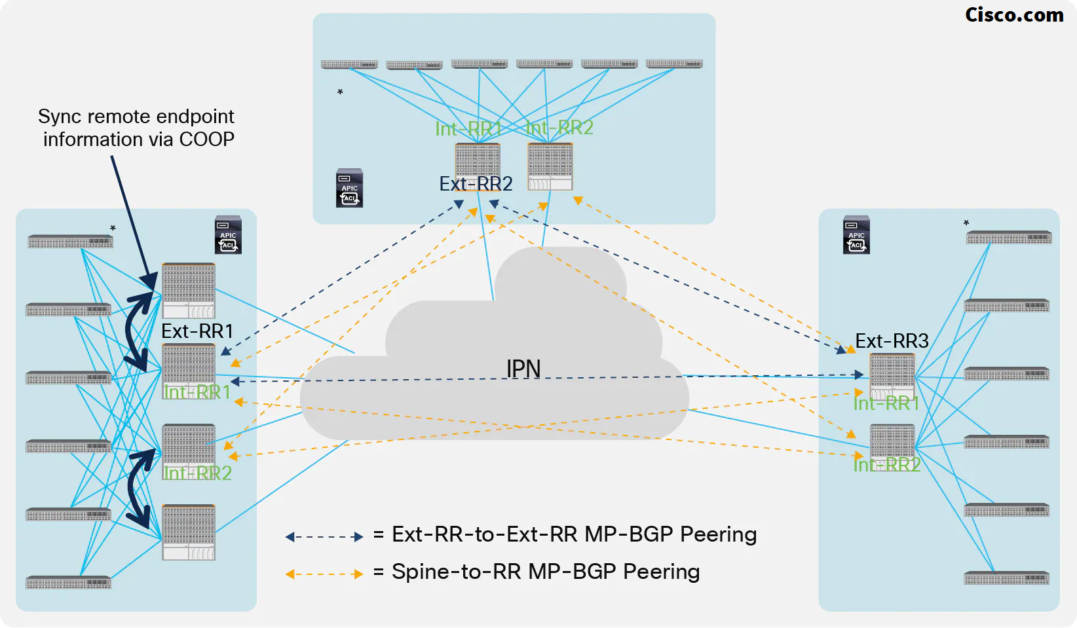
- BGP RR Considerations:
All the Pods are part of the same BGP Autonomous System, The best-practice recommendations for the deployment of Ext-RR nodes, due to specific internal implementation, are the followings:
– Ensure that any spine node that is not configured as Ext-RR is always peering with at least one Ext-RR node. Since spines do not establish intra-Pod EVPN adjacencies, this implies that a spine that is not configured as an Ext-RR node should always peer with two remote Ext-RRs (in order to continue to function if a remote Ext-RR node should fail). This means it makes little sense to configure Ext-RRs for a 2 Pods deployment since it does not provide any meaningful savings in terms of overall EVPN adjacencies that need to be established across the Pods.
– For a 3 Pods (or more) Multi-Pod fabric deployment, define one Ext-RR node in the first 3 Pods only (3 Ext-RR nodes in total):
Inter-Pods VXLAN Data Plane
- Packet flow of ARP Request and Reply with ARP Flooding Enabled:
ARP Request Flooded:
1. EP1 generates an ARP request to determine EP2’s MAC address (assuming EP1 and EP2 are part of the same IP subnet).
2. The local leaf receives the packet, inspects the payload of the ARP packet and learns EP1 information (as a locally connected endpoint), and knows the ARP request is for EP2’s IP address. Since EP2 has not been discovered yet, the leaf does not find any information about EP2 in its local forwarding tables. As a consequence, since ARP flooding is enabled, the leaf picks the FTAG associated with one of the multi-destination trees used for BUM traffic and encapsulates the packet into a multicast packet (the external destination address is the GIPo associated with the specific BD). While performing the encapsulation, the leaf also adds to the VXLAN header the S_Class information relative to the End Point Group (EPG) that EP1 belongs to.
3. The designated spine sends the encapsulated ARP request across the IPN, still leveraging the same GIPo multicast address as the destination of the VXLAN encapsulated packet (In recent releases, only the FTAG0 of the BD group is used for IGMP report to IPN) . The IPN network must have built a proper state to allow for the replication of the traffic toward all the remote Pods where this specific BD has been deployed.
4. One of the spine nodes in Pod2 receives the packet (this is the specific spine that was previously sent toward the IPN an IGMP Join for the multicast group associated with the BD) and floods it along a local multi-destination FTAG tree. Notice also that the spine COOP has learned EP1 information from an MP-BGP update received from the spine in Pod1.
5. The leaf where EP2 is connected receives the flooded ARP request, learns EP1 information (location and class-id), and forwards the packet to all the local interfaces part of the BD.
6. EP2 receives the ARP request and this triggers its reply allowing then the fabric to discover it (i.e. it is not a ‘silent host’ anymore).
ARP Reply (Unicast):
7. EP2 generates a unicast ARP reply destined to EP1 MAC address.
8. The local leaf has now EP1 location information so the frame is VXLAN encapsulated and destined to Leaf 4 in Pod1. At the same time, the local leaf also discovers that EP2 is locally connected and informs the local spine nodes via COOP.
9. The remote leaf node in Pod1 receives the packet, decapsulates it, learns and programs in the local tables EP2 location and class-id information and forwards the packet to the interface where EP1 is connected. EP1 is hence able to receive the ARP reply.
- Packet flow of ARP Request without ARP Flooding Enabled:
Without ARP flooding allowed in the Bridge Domain, the leaf nodes are not allowed to flood the frame along the local multi-destination tree, so in order to ensure the ARP request can be delivered to a remote endpoint for allowing its discovery, a process named “ARP Gleaning” has been implemented:
Use of ARP Glean Messages across Pods
1. EP1 generates an ARP request to determine EP2’s MAC address.
2. The local leaf does not have EP2’s information but since ARP flooding is disabled it encapsulates the ARP request toward one of the Proxy Anycast VTEP addresses available on the local spine nodes (no flooding along the local multi-destination tree is allowed).
3. The receiving spine decapsulates the packet and since it does not have EP2 information, an ARP Glean message is sent out to all the local leaf edge interfaces part of the same BD and also in the IPN network.
The ARP Glean message is an L2 broadcast ARP request sourced from the MAC address associated with the BD. As a consequence, it must be encapsulated into a multicast frame before being sent out toward the IPN. The specific multicast group 239.255.255.240 is used for sourcing ARP Glean messages for all the BDs (instead of the specific GIPo normally used for BUM traffic in a BD).
4. One of the spine nodes in the remote Pod previously sent an IGMP to join for the 239.255.255.240 group (since the BD is locally defined), so it receives the packet, performs VXLAN decapsulation, and generates an ARP Glean message that is sent to all the leaf nodes inside the Pod, so it reaches also the specific leaf where EP2 is locally connected.
5. The leaf receives the Glean message and forwards it to EP2.
6. EP2 sends the ARP reply, and the packet is locally consumed by the leaf (since the destination MAC is the one associated with the SVI of the BD locally defined), which learns EP2 location information.
Notes and considerations for ARP gleaning process:
- The ARP Gleaning mechanism is only possible when an IP address is configured for the Bridge Domain. For this reason, even in cases where the ACI fabric is only used for Layer 2 services (for example when deploying an externally connected default gateway), the recommendation is to configure an IP address in the BD when the goal is to disable ARP flooding (this IP address clearly must be different from the external default gateway used by the endpoints part of the BD).
- As previously mentioned, the destination IP address of the encapsulated ARP Glean frame sent into the IPN is a specific multicast address (239.255.255.240), which is used for performing ARP gleaning for all the defined Bridge Domains. Since this multicast group is normally different from the range used for flooding Bridge Domain’s traffic (each BD by default makes use of a GIPo part of the 225.0.0.0/15 range), it is critical to ensure the IPN network is properly configured to handle this traffic.
ACI Multi-Pod Scalability Limitations
As for the release of ACI 5.2:
- Maximum number of Pods: 12 (7 nodes APIC cluster should be deployed in this case).
- The maximum number of Leaf nodes across all Pods:
– 500 with a 7 nodes APIC cluster (from ACI release 4.2(4))
– 300 with a 5 nodes APIC cluster
– 200 with a 4 nodes APIC cluster (from ACI release 4.0(1))
– 80 with a 3 nodes APIC cluster
- Maximum number of Leaf nodes per Pod: 400
- Maximum number of Spine nodes per Pod: 6