
Cisco ACI – APIC Database sharding [explained]
![Cisco ACI – APIC Database sharding [explained]](https://learnduty.com/wp-content/uploads/2022/01/Cisco-ACI-APIC-Database-sharding-1-e1647904550433.jpg)
Contents
What is APIC Database sharding:
The APIC cluster uses a large database technology called sharding. This technology provides scalability and reliability to the data sets generated and processed by the APIC. The data for APIC configurations is partitioned into logically bounded subsets called shards which are analogous to database shards.
A shard is a unit of data management, and the APIC manages shards in the following ways:
- Each shard has three replicas.
- Shards are evenly distributed across the appliances that comprise the APIC cluster.
One or more shards are located on each APIC appliance. The shard data assignments are based on a predetermined hash function, and a static shard layout determines the assignment of shards to appliances.
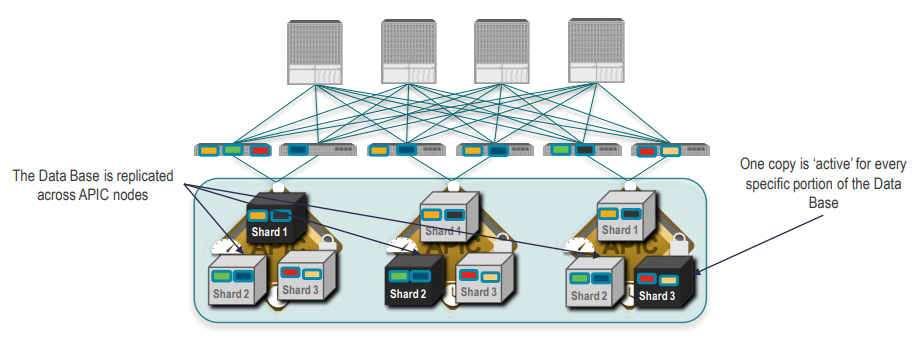
The basic idea behind sharding is that the data repository is split into several database units, known as ‘shards’. Data is placed in a shard, and that shard is then replicated three times, with each copy assigned to a specific APIC appliance. The distribution of shards across a cluster of three nodes is shown in the Figure below.
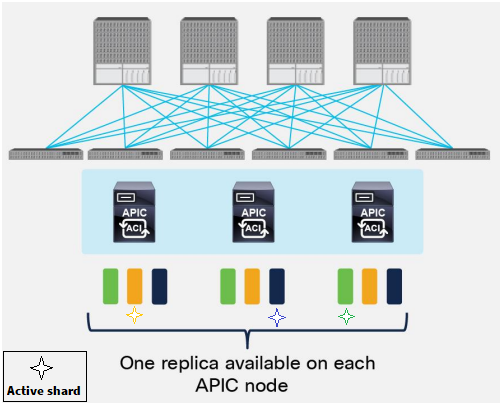
For each replica, a shard leader is elected, with write operations occurring only on the elected leader. Therefore, requests arriving at a Cisco APIC are redirected to the Cisco APIC that carries the shard leader.
Each replica in the shard has a use preference, and write operations occur on the replica that is elected leader. Other replicas are followers and do not allow write operations.
If a shard replica residing on a Cisco APIC loses connectivity to other replicas in the cluster, that shard replica is said to be in a minority state. A replica in the minority state cannot be written to (that is, no configuration changes can be made). However, a replica in the minority state can continue to serve read requests. If a cluster has only two Cisco APIC nodes, a single failure will lead to a minority situation. However, because the minimum number of nodes in a Cisco APIC cluster is three, the risk that this situation will occur is extremely low.
Shard forming during the Fabric Discovery (cluster forming)
The ACI fabric uses an infrastructure space, which is securely isolated in the fabric and is where all the topology discovery, fabric management, and infrastructure addressing is performed. ACI fabric management communication within the fabric takes place in the infrastructure space through internal private IP addresses. This addressing scheme allows the APIC to communicate with fabric nodes and other Cisco APIC controllers in the cluster. The APIC discovers the IP address and node information of other Cisco APIC controllers in the cluster using the Link Layer Discovery Protocol (LLDP)-based discovery process.
The following describes the APIC cluster discovery process:
- Each APIC in the Cisco ACI uses an internal private IP address to communicate with the ACI nodes and other APICs in the cluster. The APIC discovers the IP address of other APIC controllers in the cluster through the LLDP-based discovery process.
- APICs maintain an appliance vector (AV), which provides a mapping from an APIC ID to an APIC IP address and a universally unique identifier (UUID) of the APIC. Initially, each APIC starts with an AV filled with its local IP address, and all other APIC slots are marked as unknown.
- When a switch reboots, the policy element (PE) on the leaf gets its AV from the APIC. The switch then advertises this AV to all of its neighbors and reports any discrepancies between its local AV and neighbors’ AVs to all the APICs in its local AV.
Using this process, the APIC learns about the other APIC controllers in the ACI through switches. After validating these newly discovered APIC controllers in the cluster, the APIC controllers update their local AV and program the switches with the new AV. Switches then start advertising this new AV. This process continues until all the switches have identical AV and all APIC controllers know the IP address of all the other APIC controllers.
APIC Cluster failure use cases:
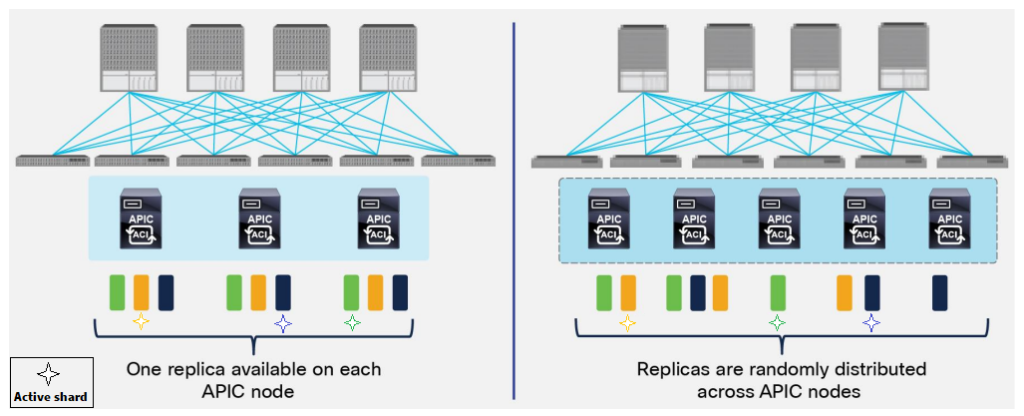
In the 3 nodes APIC cluster deployment scenario, one replica for each shard is always available on every APIC node, but this is not the case when deploying a five nodes cluster. This behavior implies that increasing the number of APIC nodes from 3 to 5 does not improve the overall resiliency of the cluster, but only allows supporting a higher number of leaf nodes. In order to better understand this, let’s consider what happens if two APIC nodes fail at the same time.
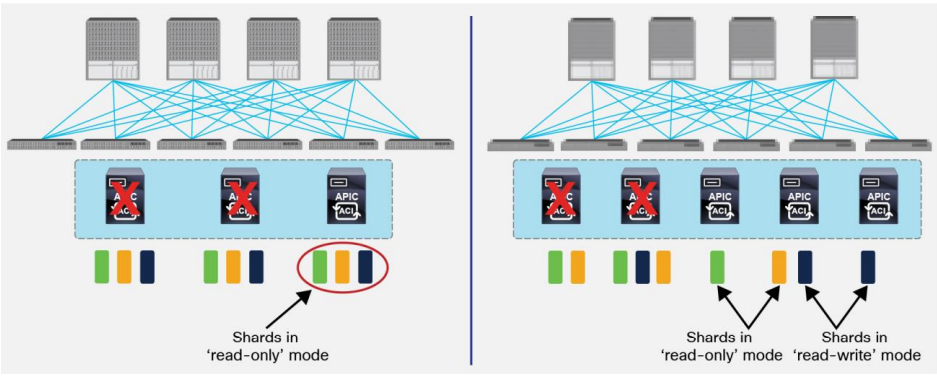
For 3 Node APIC clusters:
- APIC will allow read-only access to the DB when only one node remains active (standard DB quorum)
- Hard failure of two nodes cause all shards to be in ‘read-only’ mode
For 5 nodes APIC Clusters:
- Additional APIC will increase the system scale (up to 7* nodes supported) but does not add more redundancy
- Hard failure of two nodes would cause inconsistent behaviour across shards (some will be in ‘read-only’
mode, some in ‘read-write’ mode)

![OSPF DR and BDR Election Explained [with Configuration]](https://learnduty.com/wp-content/uploads/2022/03/image-33.png?v=1647900046)
![OSPF Neighbor Adjacency Requirements [With Configuration]](https://learnduty.com/wp-content/uploads/2022/03/image-23-418x450.png?v=1647900064)
![OSPF Neighbor States Explained [Step by Step]](https://learnduty.com/wp-content/uploads/2022/03/image-13.png?v=1647900076)
![OSPF Area Types Explained and Configuration [Demystified]](https://learnduty.com/wp-content/uploads/2022/03/image-8.png?v=1647900083)